
SQL: Indíces
Hablar de índices es pasar de ser un “escritor de queries” a ser un optimizador de rendimiento. En una base de datos de alto nivel, los índices son la diferencia entre una aplicación que responde al instante y una que se congela.
Un índice es una estructura de datos física (generalmente un B-Tree en PostgreSQL) que el motor de búsqueda utiliza para localizar filas de forma rápida sin tener que leer toda la tabla.
El “Trade-off” (Intercambio):
- Ganancia: Velocidad extrema en lecturas (
SELECT) y filtrados (WHERE). - Costo: Espacio adicional en disco y una ligera penalización en escrituras (
INSERT,UPDATE,DELETE), ya que cada vez que cambias un dato, el índice también debe actualizarse.
La Prueba de Fuego: EXPLAIN ANALYZE
Antes de crear el índice, vamos a pedirle a PostgreSQL que nos diga cuánto le cuesta buscar un registro específico. Queremos buscar atenciones con un costo base muy específico o un diagnóstico.
Con base en el siguiente esquema relacional:
-- Ejecuta esto y observa el "Execution Time" y el "Sequential Scan"
EXPLAIN ANALYZE
SELECT * FROM atenciones
WHERE costo_base = 500.55;
¿Qué buscar en el resultado?
Verás algo llamado “Seq Scan” (Sequential Scan). Esto significa que PostgreSQL leyó todas las 100,000+ filas una por una para encontrar el dato. Es lo más ineficiente que existe.

Creación del Índice
Ahora, creamos un índice sobre la columna costo_base.
CREATE INDEX idx_atenciones_costo ON atenciones(costo_base);
Ejecutar el mismo EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT * FROM atenciones
WHERE costo_base = 500.55;

Ahora verás “Index Scan” o “Bitmap Index Scan”. El tiempo de ejecución debería haber caído drásticamente (de milisegundos a nanosegundos).
Tipos de Índices
En PostgreSQL existen estrategias avanzadas:
- Índices Compuestos: Cuando filtras mucho por dos columnas a la vez (ej.
fechayurgencia).CREATE INDEX idx_fecha_urgencia ON atenciones(fecha_atencion, nivel_urgencia);
- Índices Únicos: Aseguran que no haya duplicados (Postgres los crea automáticamente para las
PRIMARY KEY). - Índices Parciales: Solo indexan una parte de la tabla. Útil si solo te interesan las urgencias críticas.
CREATE INDEX idx_criticos ON atenciones(id_atencion) WHERE nivel_urgencia = 1;- Ventaja: El índice es mucho más pequeño y rápido.
Buenas Prácticas:
- No indexar todo: Muchos índices hacen que las inserciones sean lentas. Se indexan las columnas que aparecen en el
WHERE, en elJOINo en elORDER BY. - Columnas de baja cardinalidad: No indexar columnas con pocos valores (ej. “Género” M/F). El motor preferirá hacer un escaneo secuencial.
- Mantenimiento: Usar
REINDEXoVACCUMsi la base de datos tiene mucho movimiento, para limpiar el árbol del índice.
El Reporte de Urgencias Críticas
1. El Problema
La administración está usando la vista de seguridad (v_metricas_anonimas), pero al intentar filtrar por fechas y diagnósticos específicos sobre los 100,000+ registros, el sistema tarda demasiado.
La Consulta “Lenta”:
-- Queremos los 10 costos más altos de diagnósticos 'I05' en el último año
SELECT * FROM v_metricas_anonimas
WHERE codigo_diagnostico = 'I05'
AND fecha_servicio >= '2025-01-01'
ORDER BY costo_final DESC
LIMIT 10;
Diagnóstico: El Plan de Ejecución
Ejecuta el comando EXPLAIN ANALYZE antes de la consulta.
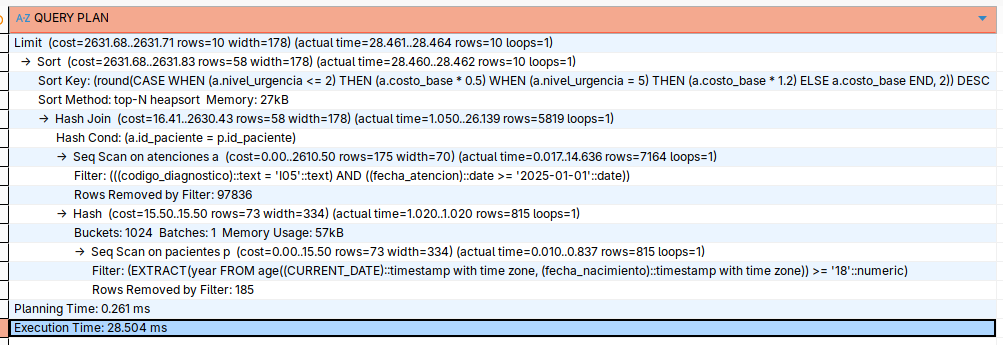
¿Qué encontrarás?
- Sequential Scan: El motor está recorriendo toda la tabla de
atenciones. - Sort Method: external merge disk: El ordenamiento es tan pesado que no cabe en la memoria RAM y usa el disco duro (esto es lentísimo).
- Execution Time: Probablemente entre 150ms y 400ms (una eternidad en términos de BD).
Estrategia de Indexación
Proponer e implementar índices para bajar el tiempo a menos de 10ms. Aquí están las pistas para la solución profesional:
A. El Índice de Búsqueda (Filtros)
Necesitamos un índice que ayude al WHERE. Como filtramos por codigo_diagnostico y fecha_atencion, lo ideal es un índice compuesto.
-- Solución Pista 1:
CREATE INDEX idx_atenciones_diag_fecha
ON atenciones (codigo_diagnostico, fecha_atencion);
B. El Índice de Ordenamiento (Performance Pro)
La consulta ordena por costo_final. Pero costo_final es un cálculo dentro de la vista. ¿Podemos indexar un cálculo? ¡En PostgreSQL sí! Se llaman Índices Expresivos.
-- Solución Pista 2: Indexar la lógica del CASE para el ordenamiento
CREATE INDEX idx_atenciones_costo_calculado ON atenciones (
(CASE
WHEN nivel_urgencia <= 2 THEN costo_base * 0.5
WHEN nivel_urgencia = 5 THEN costo_base * 1.2
ELSE costo_base
END) DESC
);
Verificación Final
Después de crear los índices, ejecutar de nuevo el EXPLAIN ANALYZE.
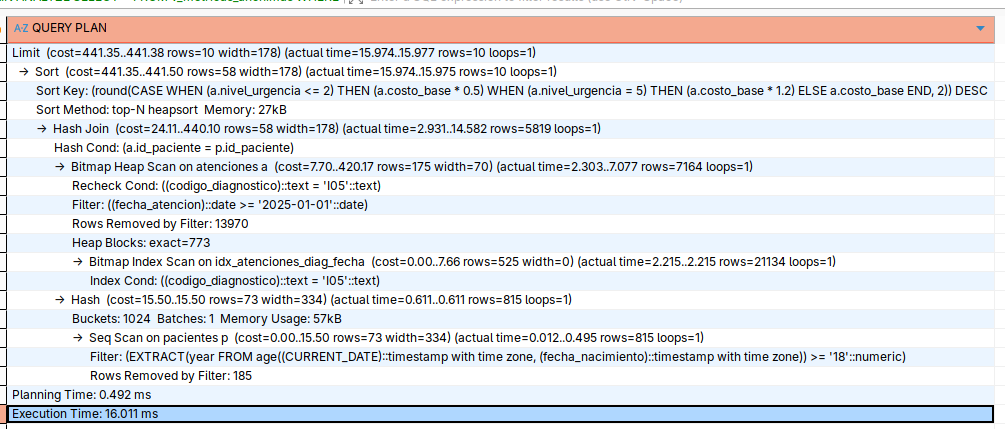
Resultado esperado:
- Index Scan: El motor ya no lee la tabla, va directo al grano.
- Execution Time: < 5ms.
- Costo de Memoria: Reducción drástica del uso de CPU.
Preguntas de Reflexión
- ¿Por qué un índice compuesto es mejor que dos índices simples en este caso?
- ¿Qué pasa con el espacio en disco después de crear estos dos índices?
- Si mañana empezamos a insertar 1,000,000 de registros por hora, ¿cómo afectan estos índices?