
Gráficos Estadísticos: la representación visual de los datos
Visualizar los datos es, en esencia, contar una historia con números. La estadística no solo trata de calcular, sino de comunicar. Dependiendo de si tus datos son números (cuantitativos) o categorías (cualitativos), la herramienta que elijas cambiará drásticamente la interpretación.
A. Gráficos para Variables Numéricas (Cuantitativas)
Estos gráficos buscan mostrar la forma, el centro y la dispersión de los datos.
| Gráfico | Construcción | Función e Interpretación |
| Histograma | Barras verticales unidas. Eje X: Intervalos de clase; Eje Y: frecuencia (). | Permite ver la forma de la distribución (simetría, sesgo) y dónde se concentran los datos. |
| Polígono de Frecuencias | Se unen con líneas los puntos medios (marcas de clase) de la parte superior de las barras del histograma. | Suaviza la visualización del histograma; útil para comparar dos o más grupos en un mismo gráfico. |
| Ojiva | Gráfico lineal que une los límites superiores de clase con la frecuencia acumulada (). | Útil para determinar cuántos datos están “por debajo de” un valor. Ayuda a calcular percentiles. |
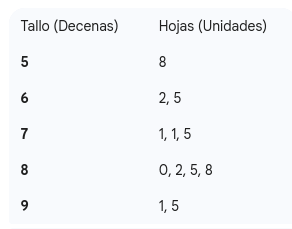
| Tallo y Hojas | Se divide cada número en un “tallo” (dígitos iniciales) y una “hoja” (último dígito). | Es un híbrido entre tabla y gráfico. Permite ver la distribución sin perder los valores originales. |
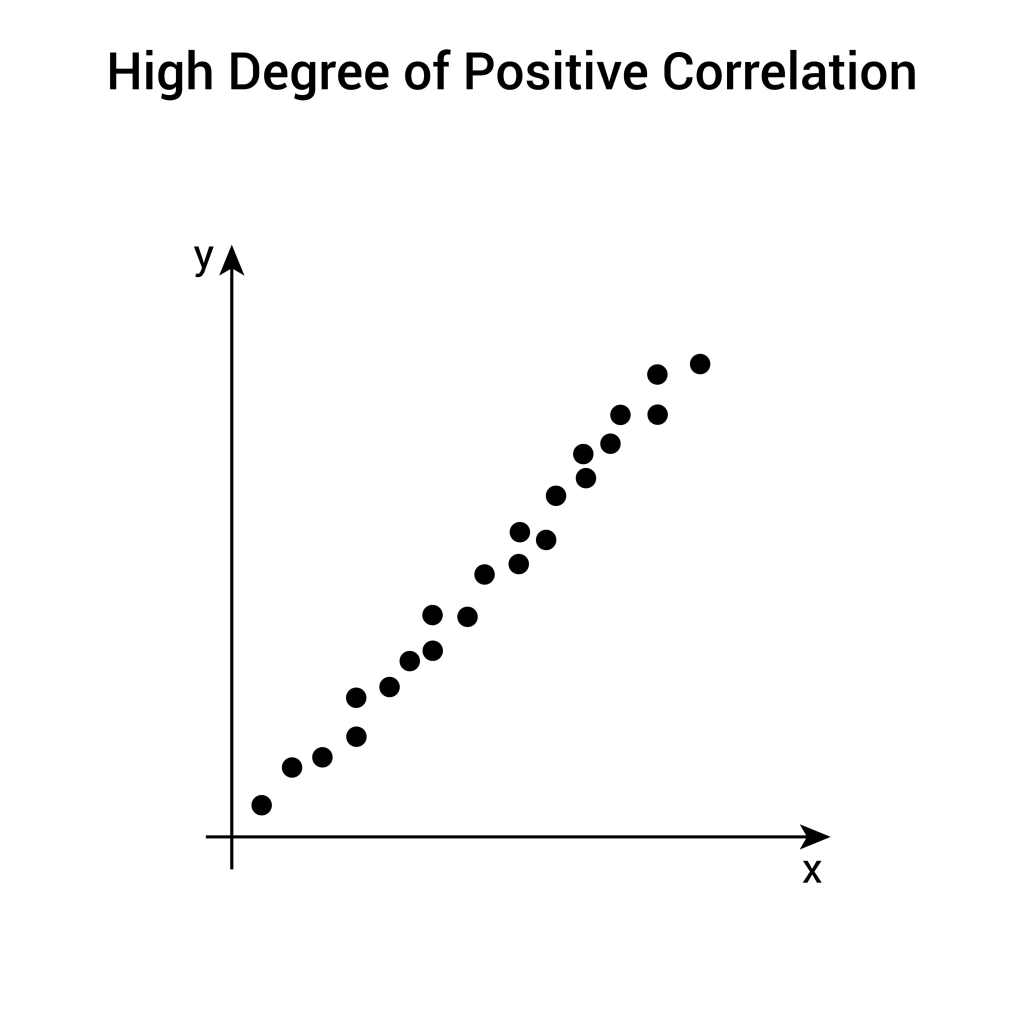
| Dispersión (Scatter) | Puntos en un plano cartesiano (X, Y). Cada punto es una observación. | Identifica la relación o correlación entre dos variables numéricas. |
| Caja y Bigote (Box Plot) | Una caja entre el primer y tercer cuartil (), una línea en la mediana y “bigotes” hasta los valores min/max. | Muestra la variabilidad, la simetría y detecta valores atípicos (outliers) de forma inmediata. |
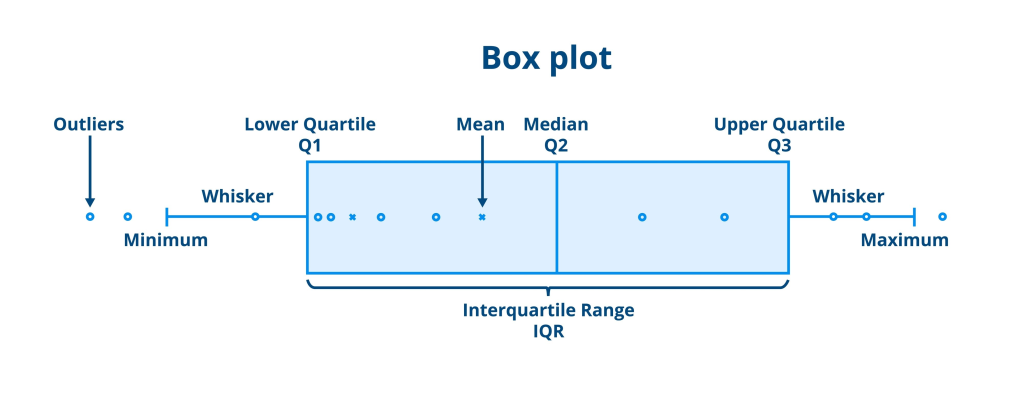
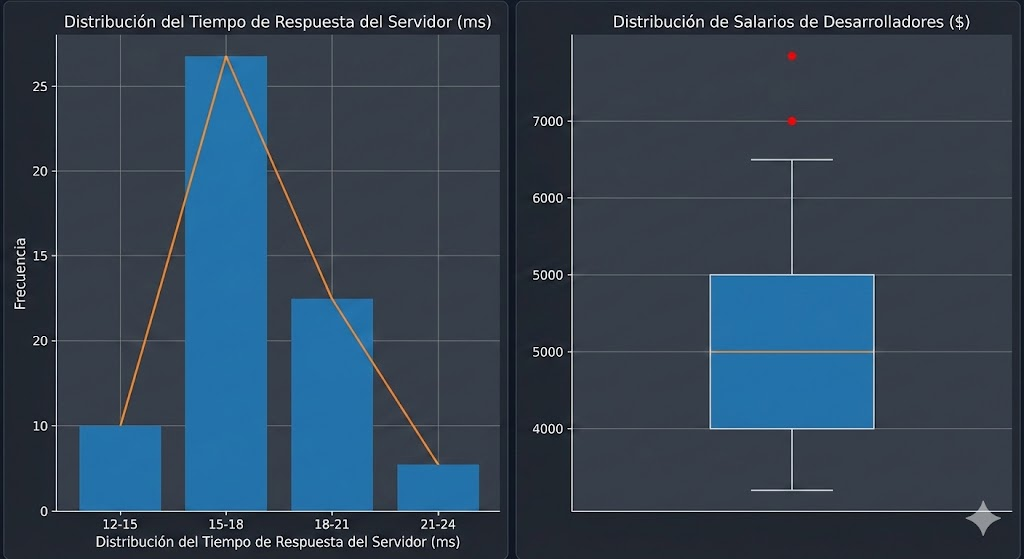
A la izquierda, el Histograma con Polígono de Frecuencias muestra cómo se distribuyen los tiempos de respuesta del servidor, evidenciando la concentración de datos entre 15 y 18 ms. A la derecha, el Diagrama de Caja y Bigotes ilustra la distribución de los salarios, destacando claramente los valores atípicos (los puntos rojos en la parte superior) que representan salarios inusualmente altos.
B. Gráficos para Variables Categóricas (Cualitativas)
Aquí no hay orden numérico; buscamos comparar grupos o ver proporciones.
- Gráfico de Tarta (Pastel): Se divide un círculo en sectores proporcionales a la frecuencia relativa. Su función es mostrar la composición del total (partes de un todo). Nota: No se recomienda si hay muchas categorías.
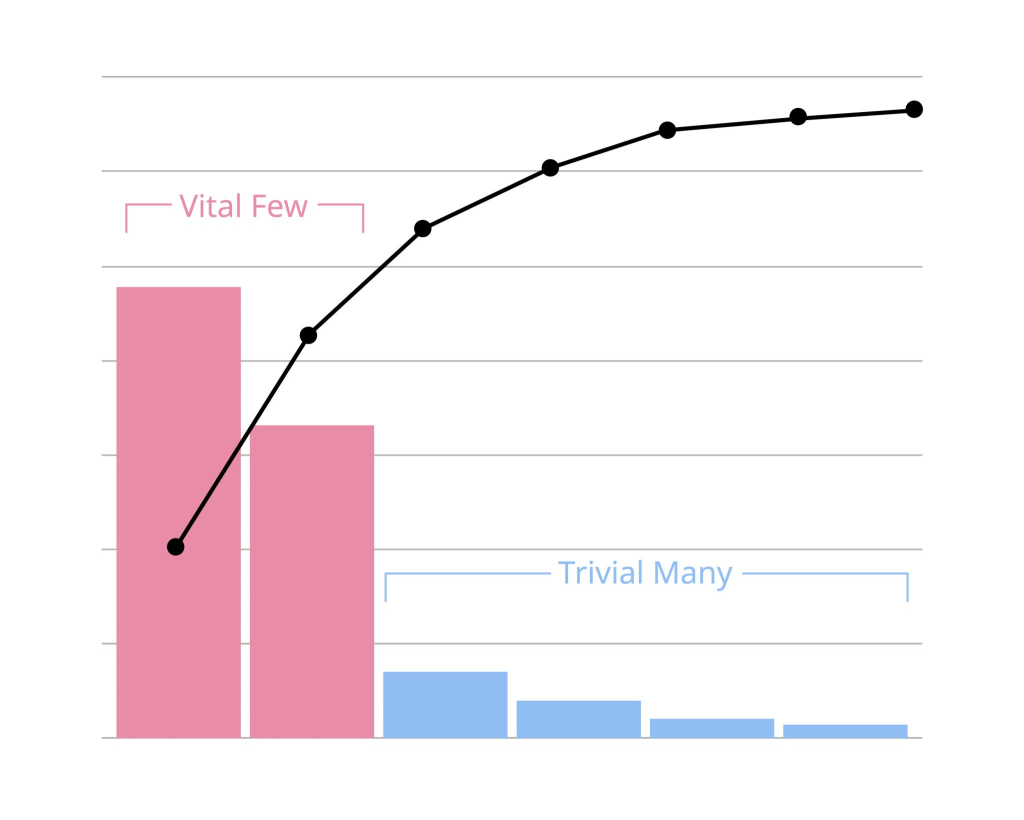
- Diagrama de Pareto: Un gráfico de barras (de mayor a menor) combinado con una línea de frecuencia acumulada. Se usa para identificar los “pocos vitales” (regla 80/20).
- Tablas Cruzadas (Contingencia): Relacionan dos variables categóricas (ej. Género vs. Preferencia de Navegador). Permiten ver si una variable depende de la otra.
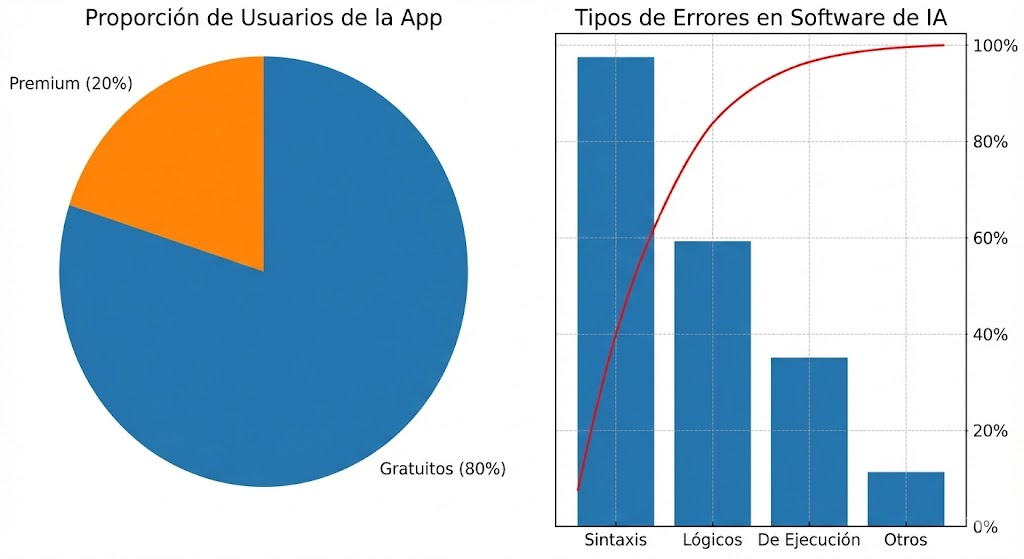
A la izquierda, el Gráfico de Pastel muestra de un vistazo la proporción 80/20 entre usuarios gratuitos y premium. A la derecha, el Diagrama de Pareto ayuda a priorizar, mostrando que la mayoría de los problemas del software de IA provienen de los errores de “Sintaxis” y “Lógicos” (la línea roja muestra cómo se acumula el porcentaje rápidamente con estas dos categorías).
C. Gráficos de Series Temporales
- Construcción: El tiempo siempre va en el eje horizontal () y la variable numérica en el vertical ().
- Función: Identificar tendencias (subidas/bajadas a largo plazo), estacionalidad (patrones que se repiten) o ciclos.
- Interpretación: Se busca detectar si la variable crece, decrece o se mantiene estable a través del tiempo.
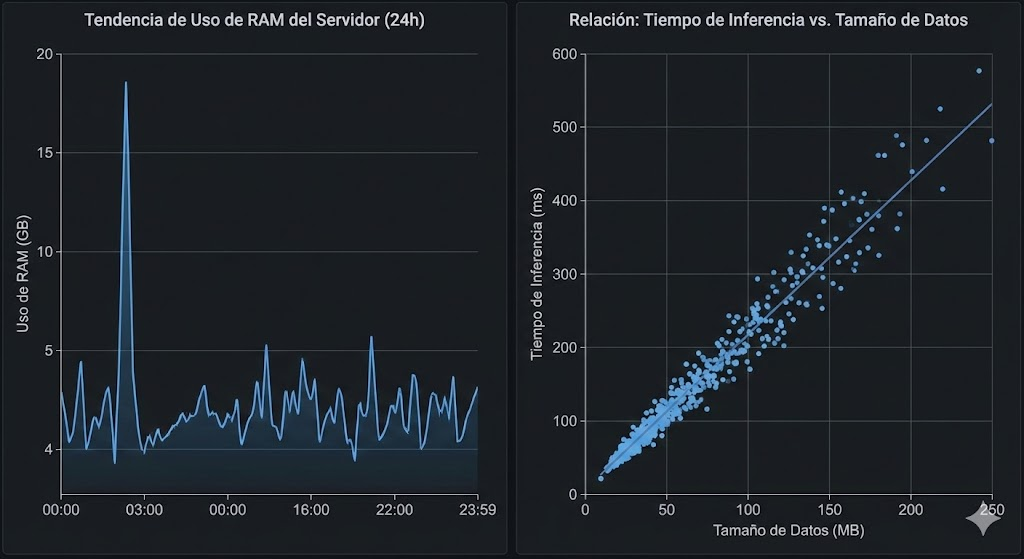
A la izquierda, el Gráfico de Líneas muestra el uso de RAM a lo largo de 24 horas, revelando un pico claro y preocupante alrededor de las 03:00 AM. A la derecha, el Gráfico de Dispersión muestra la relación entre el tamaño de los datos y el tiempo de inferencia de la IA; la tendencia ascendente de los puntos (y la línea de tendencia) confirma una fuerte correlación positiva: a más datos, más tiempo.
Errores y Engaños en la Presentación de Datos
Como la estadística puede ser “la medida de nuestra ignorancia”, a veces se usa para manipular esa ignorancia. Estos son los errores más comunes (a veces intencionales):
- El Eje Y Truncado: Iniciar el eje vertical en un número distinto de cero (ej. empezar en 90 en lugar de 0). Esto exagera las diferencias entre barras o puntos.
- Escalas Inconsistentes: Cambiar la escala en medio del eje para hacer que una subida parezca menos drástica de lo que es.
- Gráficos 3D Engañosos: Las tartas o barras en 3D distorsionan la perspectiva. Las partes que están “más cerca” del espectador parecen más grandes de lo que realmente representan en datos.
- Omisión de Contexto: Mostrar una serie temporal muy corta para ocultar una tendencia general opuesta (efecto “cherry-picking”).
Regla de oro: Un gráfico honesto debe permitir que el lector llegue a la conclusión correcta sin necesidad de leer los números específicos.