
Modelado Lógico de Bases de Datos
Este nivel de diseño es el puente que traduce las necesidades del negocio en una estructura técnica precisa, preparándolos para la implementación física.
El modelo lógico es el segundo nivel de abstracción en el diseño de bases de datos. Su función principal es añadir precisión técnica al modelo conceptual, definiendo estructuras de datos que, aunque siguen siendo independientes de un software específico (como Oracle o MySQL), ya responden a un modelo de datos particular, generalmente el modelo relacional.
En esta etapa, se deja de hablar únicamente de “entidades” y “relaciones” conceptuales para definir:
- Atributos detallados: Se especifican nombres de columnas y se asignan tipos de datos genéricos (como INTEGER o VARCHAR).
- Claves Primarias (Primary Keys): Identificadores únicos para cada registro en una tabla.
- Claves Foráneas (Foreign Keys): Atributos que establecen vínculos entre tablas al referenciar la clave primaria de otra.
- Estructuras de tablas (Relaciones): La organización de los datos en filas (tuplas) y columnas (atributos).
A diferencia del modelo conceptual, que busca el alineamiento con los interesados del negocio, el modelo lógico busca la precisión estructural necesaria para un arquitecto de datos.
El diseño lógico se inicia inmediatamente después de haber validado el esquema conceptual con los usuarios. Se utiliza en el momento en que ya sabemos qué datos necesitamos capturar (fase conceptual) y ahora debemos decidir cómo se estructurarán técnicamente.
Es fundamental no saltar esta fase por las siguientes razones:
- Independencia del SGBD: Permite evaluar el diseño por sus propios méritos antes de comprometerse con una tecnología específica (PostgreSQL, MySQL, etc.).
- Detección de errores costosos: Corregir errores estructurales en esta fase es significativamente más barato que hacerlo cuando la base de datos ya está en producción.
- Punto de partida para la normalización: Es el nivel donde se aplican las reglas para eliminar la redundancia e inconsistencias.
Fundamentos para un Modelo Lógico Robusto
El Modelo Relacional y su Notación
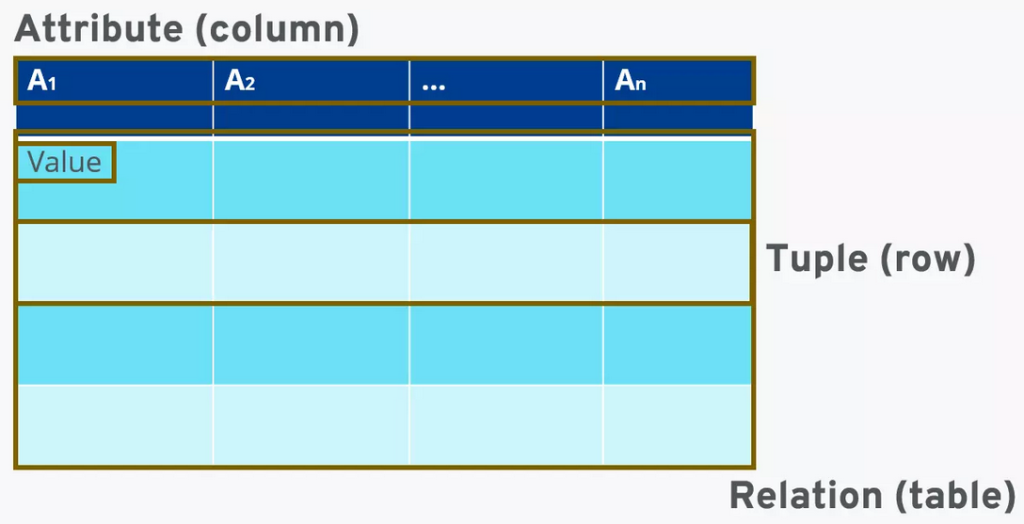
En este modelo toda la información se representa lógicamente mediante tablas.
- Relación (Tabla): Se define como un conjunto de datos organizados lógicamente. En este modelo, el orden de los registros no posee relevancia, lo que facilita su manipulación y comprensión por parte del usuario.
- Tupla (fila o registro): Cada tupla constituye una instancia única de la entidad que se está modelando.
- Atributos: Cada columna representa una propiedad de esa entidad.
- Dominio: Es el conjunto de valores permitidos para un atributo determinado (por ejemplo, integer, date, string). Es fundamental que todos los valores en un atributo sean atómicos, es decir, que no se admitan grupos repetitivos o datos multivalorados en una sola celda.
- Grado y Cardinalidad: El número de columnas y filas, respectivamente.
Reglas de Transformación (Mapping)
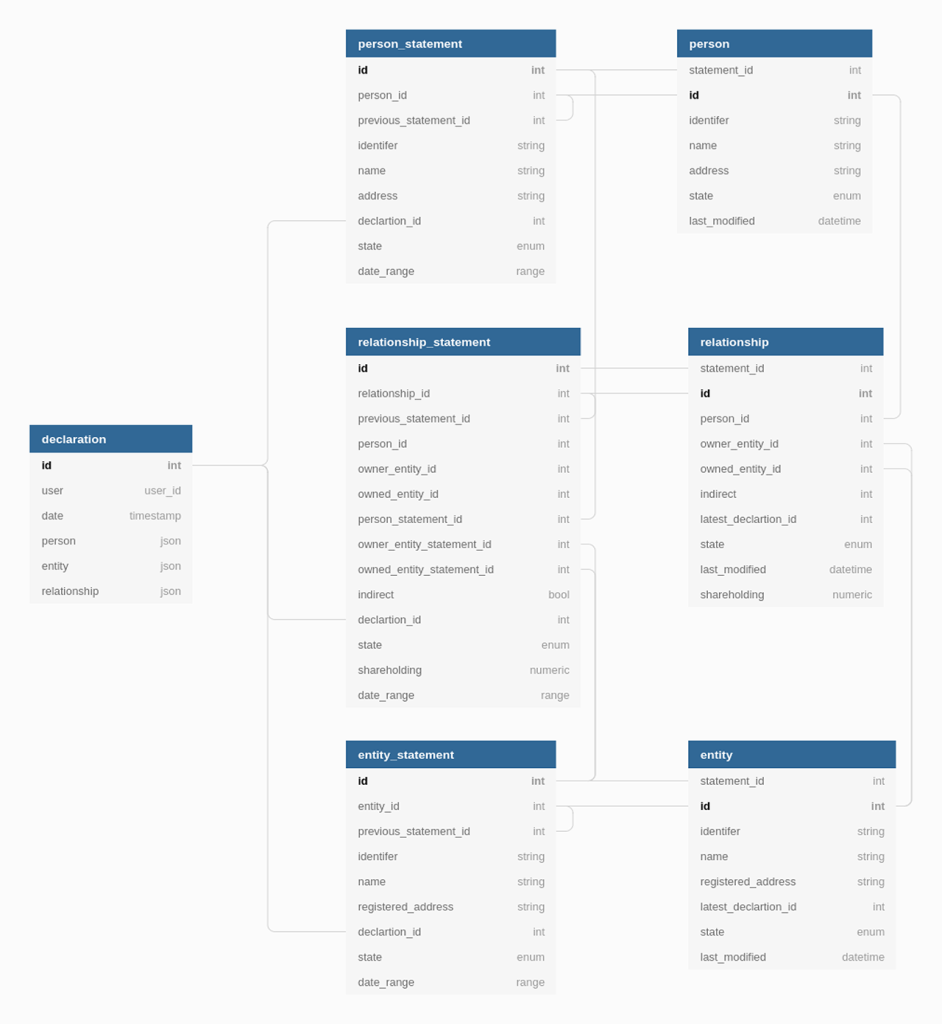
Para pasar del DER al modelo lógico, existen reglas de derivación estrictas que deben seguir:
- Entidades a Tablas: Cada tipo de entidad se convierte en una relación o tabla.
- Atributos a Columnas: Los atributos identificadores se convierten en claves primarias y los demás en columnas simples.
- Atributos simples: Cada atributo de la entidad se transforma en una columna de la tabla.
- Atributos identificadores: Los atributos marcados como claves primarias en el DER se convierten en la Clave Primaria (Primary Key) de la tabla, debiendo ser subrayados en la notación formal. Se debe asegurar que estos valores sean únicos y no nulos.
- Atributos compuestos: No se permiten estructuras jerárquicas en el modelo relacional; por lo tanto, un atributo compuesto (como “Dirección”) debe descomponerse en sus componentes atómicos (Calle, Número, Ciudad) como columnas individuales.
- Atributos Multivalorados: Dado que el modelo relacional exige la atomicidad de los datos (Primera Forma Normal), no se pueden almacenar múltiples valores en una sola celda. Existen tres métodos para resolver esto:
- Creación de una nueva relación (Recomendado): Se crea una tabla independiente que contenga el atributo multivalorado y la clave primaria de la entidad original como clave foránea.
- Ampliación de la clave: Se incluye el atributo multivalorado como parte de una clave primaria compuesta en la tabla original, aunque esto suele generar redundancia indeseada.
- Columnas finitas: Si se conoce el límite máximo de valores, se pueden crear columnas numeradas (ej. Teléfono1, Teléfono2), aunque esta práctica genera valores nulos y rigidez en el diseño.
- Interrelaciones N:M: Se transforman en una nueva tabla intermedia que contiene las claves de ambas entidades como claves foráneas. Añadir cualquier atributo propio que posea la relación en el DER
- Interrelaciones 1:N: Generalmente se resuelven propagando la clave primaria del lado “1” hacia la tabla del lado “N” como clave foránea. Si la relación posee atributos propios, estos también se propagan hacia el lado “N”.
- Interrelaciones Uno a Uno (1:1): No existe una regla fija, pero se recomienda:
- Si una entidad tiene participación opcional y la otra obligatoria se debe propagar la clave de la obligatoria hacia la opcional para minimizar valores nulos.
- En casos de simetría, se puede elegir cualquier dirección o incluso fusionar ambas entidades en una sola tabla si el contexto del negocio lo permite y beneficia el rendimiento

Teoría de la Normalización
Este es el corazón de la disciplina en el nivel lógico. La normalización consiste en descomponer tablas complejas en estructuras más pequeñas y estables para evitar anomalías de inserción, borrado y actualización.
- Primera Forma Normal (1FN): Exige que todos los atributos sean atómicos (un solo valor por celda) y que no haya grupos repetitivos.
- Segunda Forma Normal (2FN): Debe estar en 1FN y cada atributo no clave debe depender totalmente de la clave primaria.
- Tercera Forma Normal (3FN): Debe estar en 2FN y no deben existir dependencias transitivas (atributos que dependen de otros atributos que no son clave).
Restricciones de Integridad
Un modelo es robusto solo si garantiza la calidad de los datos mediante:
- Integridad de Entidad: Ninguna clave primaria puede ser nula (NOT NULL).
- Integridad Referencial: Asegura que los valores de las claves foráneas coincidan con valores existentes en la tabla referenciada.
- Restricciones de Dominio: Definir los valores permitidos para cada atributo (tipos de datos, rangos, valores por defecto).
Mejores Prácticas de Diseño
Finalmente, para lograr un nivel profesional, es importante aplicar una convención de nombres consistente para todos los objetos, seleccionar el tamaño de dato adecuado para cada columna para optimizar el espacio y mantener la documentación actualizada, como el diccionario de datos, para facilitar el mantenimiento futuro.