
Técnicas de Muestreo
Las Técnicas de Muestreo son la piedra angular de la Estadística Inferencial, ya que el método define la validez de las conclusiones.
1. Muestreo Probabilístico
El muestreo probabilístico es aquel donde todos los elementos de la población tienen una probabilidad conocida, distinta de cero, de ser seleccionados para la muestra. Es el único método que permite hacer inferencia estadística y generalizar resultados a la población con un nivel de confianza cuantificable.
| Tipo de Muestreo | Descripción | Aplicación Principal |
| Aleatorio Simple (MAS) | Cada elemento de la población tiene la misma probabilidad de ser seleccionado. Es como sacar nombres de un sombrero (con reposición). | Poblaciones pequeñas y homogéneas donde se tiene una lista completa de todos los elementos. |
| Sistemático | Se selecciona el primer elemento al azar, y luego se elige cada -ésimo elemento a partir de ese. es el coeficiente de elevación (). | Ideal cuando la población está ordenada (ej. lista de clientes, línea de producción). Es fácil de implementar. |
| Estratificado | La población se divide en subgrupos mutuamente excluyentes y homogéneos llamados estratos (ej. por género, edad, región). Luego se selecciona una muestra aleatoria simple de cada estrato. | Cuando se necesita asegurar que subgrupos específicos (estratos) estén representados en las proporciones correctas. |
| Conglomerados | La población se divide en subgrupos heterogéneos llamados conglomerados (ej. ciudades, barrios). Se seleccionan algunos conglomerados al azar, y todos los elementos dentro de los conglomerados elegidos forman la muestra. | Ideal para poblaciones geográficamente dispersas, ya que reduce costos de viaje y logísticos. |
a) Grupos Mutuamente Excluyentes (Disjuntos)
En Estadística y Probabilidad, dos o más grupos o eventos son mutuamente excluyentes si no pueden ocurrir al mismo tiempo o si un elemento no puede pertenecer a más de uno de esos grupos simultáneamente.
- Criterio: La intersección de los conjuntos es vacía ().
- Contexto de Grupos: Se usa para dividir una población de tal manera que cada individuo caiga en una sola categoría.
| Característica | Ejemplo |
| Evento | Lanzar un dado: El evento “sacar un 2” y el evento “sacar un 5” son mutuamente excluyentes en un solo lanzamiento. |
| Grupos | Clasificación por Género (Femenino o Masculino). Una persona no puede ser clasificada en ambos grupos a la vez. |
| Muestreo | La división de la población en Estratos para el Muestreo Estratificado (un individuo pertenece a un único estrato). |
b) Grupos Homogéneos (Similares Internamente)
Un grupo o conjunto de datos es homogéneo cuando todos los elementos dentro de él comparten características muy similares o sus valores de variables muestran muy poca variabilidad (dispersión).
- Criterio Estadístico: La Varianza o la Desviación Estándar de los elementos dentro del grupo es muy baja, o idealmente, cero.
- Contexto de Muestreo: La homogeneidad es el objetivo principal al dividir la población en Estratos (Muestreo Estratificado).
| Característica | Ejemplo |
| Datos | Un grupo de personas donde todas tienen exactamente 30 años. |
| Muestreo | Un Estrato de “Estudiantes de primer año de Ingeniería”. Se espera que compartan características académicas y de edad similares. |
| Objetivo | Reducir la muestra necesaria, ya que al ser similares, estudiar uno es casi como estudiar a todos. |
c) Grupos Heterogéneos (Diversos Internamente)
Un grupo o conjunto de datos es heterogéneo cuando los elementos dentro de él son diversos y presentan una gran variabilidad o diferencia en sus características.
- Criterio Estadístico: La Varianza o la Desviación Estándar de los elementos dentro del grupo es alta.
- Contexto de Muestreo: La heterogeneidad es una característica que se busca en los Conglomerados (Muestreo por Conglomerados).
| Característica | Ejemplo |
| Datos | Una muestra de edad de 18, 35, 50, 78 años. Hay mucha dispersión interna. |
| Muestreo | Un Conglomerado de “Todas las viviendas en el Barrio X”. Se espera que dentro del barrio haya una mezcla heterogénea de edades, ingresos y ocupaciones. |
| Objetivo | Que un solo grupo (el conglomerado) represente la diversidad de la población total. |
2. Muestreo No Probabilístico
En este tipo de muestreo, la selección de los elementos no se basa en el azar, sino en el criterio del investigador o en la facilidad de acceso.
- Desventaja: No se puede calcular el error de muestreo ni se puede garantizar que la muestra sea representativa de la población. Las conclusiones no pueden generalizarse estadísticamente.
- Usos: Estudios exploratorios, estudios de casos o cuando no se tiene acceso a una lista completa de la población.
| Tipo de Muestreo | Descripción |
| Por Conveniencia | Se selecciona a los individuos que están fácilmente disponibles o que son más fáciles de contactar. |
| Por Juicio o Criterio | El investigador utiliza su experiencia para seleccionar a los individuos que cree que son los más adecuados para el estudio. |
| Por Cuotas | La población se divide en grupos (como el estratificado), pero el investigador llena las cuotas de cada grupo de manera no aleatoria (por conveniencia o criterio). |
| Bola de Nieve | Se contacta a unos pocos individuos clave, y estos, a su vez, identifican a otros que cumplen con los criterios del estudio. |
3. Proceso del Diseño de una Muestra
El diseño de una muestra es un proceso sistemático que garantiza que el estudio sea válido y los resultados sean fiables.
Fases del Diseño de la Muestra
| Fase | Tarea Principal | Relevancia Estadística |
| 1. Definición de la Población | Definir claramente a quién se quiere estudiar (Unidad de Análisis, Alcance Geográfico, Marco Temporal). | Determina el Parámetro de interés (, ). |
| 2. Definición de la Variable y Tipo | Identificar la Variable Estadística a medir y determinar su Tipo (Nominal, Ordinal, Discreta, Continua). | Define el tipo de análisis que se puede realizar (ej. calcular la media solo es válido para Cuantitativas). |
| 3. Selección de la Técnica de Muestreo | Elegir entre un método Probabilístico (si se necesita inferencia) o No Probabilístico (si es exploratorio). | Define la validez y generalización de los resultados. |
| 4. Determinación del Tamaño de Muestra () | Calcular el número mínimo de elementos necesarios para que el Estadístico estimado sea preciso (es decir, esté cerca del Parámetro). | Se basa en el nivel de confianza, margen de error y variabilidad esperada de la población. |
Fórmula del Tamaño de Muestra
Para el muestreo probabilístico, el cálculo del tamaño de muestra () se basa en la Estadística Inferencial. Una fórmula común para estimar una proporción () en poblaciones grandes es:
n = \frac{Z^2 \times P \times (1 - P)}{E^²}Donde:
- : Tamaño de la muestra.
- : Nivel de confianza (ej. para 95% de confianza).
- : Proporción poblacional estimada (se usa 0.5 si es desconocida), representa la proporción (o probabilidad) del evento de interés que se espera encontrar en la población total.
- : Margen de error aceptable.
Para muestras de población finita:
\begin{align*}
n_0 & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
n & = \frac{n_0}{1 + \frac{n_0}{N}}
\end{align*}La fórmula de tamaño de muestra para poblaciones infinitas es:
n = \frac{Z^2 \times \sigma^2}{E^2}Donde:
- : Tamaño de la muestra requerido.
- : Valor Z asociado al Nivel de Confianza (ej. 1.96 para 95%).
- : Varianza poblacional (el cuadrado de la Desviación Estándar Poblacional, σ).
- : Error Máximo Aceptable (la precisión deseada, expresada en las mismas unidades de la variable, ej. 2 años, 500 pesos).
Como la desviación estándar poblacional () generalmente es desconocida antes de realizar el estudio, hay tres formas comunes de estimarla:
- Estudios Piloto: Se realiza una pequeña muestra preliminar y se calcula la desviación estándar muestral () para usarla como una estimación de .
- Estudios Previos: Se utiliza la desviación estándar reportada en investigaciones similares recientes.
- Rango Estimado (Estimación Conservadora): Se estima el rango () de valores posibles de la variable y se utiliza la regla empírica: o (dependiendo de la distribución esperada).
Proceso con Información Incompleta
Paso 1: Definir el Parámetro y Usar el Caso Más Conservador
Lo primero es definir si tu estudio busca una media () o una proporción ():
A. Si buscas una Proporción ()
- Solución: Usa el valor que maximiza la varianza: .
- Justificación: Usar garantiza que el tamaño de muestra calculado () sea el más grande posible para cualquier proporción, asegurando que el error se cumpla con el nivel de confianza .
B. Si buscas una Media (μ)
- Solución: Debes estimar la desviación estándar ( o ). Como es desconocida, usas un método de estimación conservadora: el método del rango.
- Estimar el rango (R): Determina el valor máximo (Máx) y el valor mínimo (Mín) posible o razonable para tu variable de estudio (ej. edad, salario, tiempo de espera).
- Estimar : Divide el rango entre 4 (esta es una regla empírica conservadora basada en la distribución normal).
- Estimar el rango (R): Determina el valor máximo (Máx) y el valor mínimo (Mín) posible o razonable para tu variable de estudio (ej. edad, salario, tiempo de espera).
Paso 2: Aplicar la Fórmulas para Población Infinita ()
Paso 3: Aplicar la Corrección por Población Finita
Determinación del valor de
El valor de (el puntaje o valor crítico ) es un elemento fundamental en la Estadística Inferencial y en el cálculo del tamaño de muestra, ya que está directamente ligado al Nivel de Confianza que deseamos para nuestro estudio.
El valor de se obtiene de la Tabla de la Distribución Normal Estándar (también conocida como la tabla ) y representa el número de desviaciones estándar que una observación está por encima o por debajo de la media.
El Nivel de Confianza (NC) es la probabilidad de que el intervalo que construyamos contenga el verdadero parámetro poblacional.
El valor que utilizamos es el valor crítico que define las fronteras de esa área de confianza en la distribución.
Pasos para Obtener el Valor de Z
El proceso se basa en la simetría de la distribución normal y en el error que estamos dispuestos a aceptar.
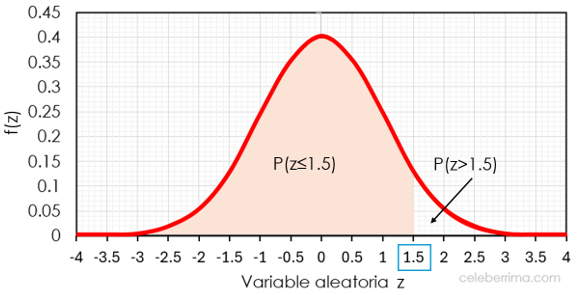
1. Definir el Nivel de Confianza (NC):
- Es el porcentaje de certeza que queremos (ej. 90%, 95%, 99%).
- Se expresa como un valor decimal (ej. 0.90, 0.95, 0.99).
2. Calcular el Nivel de Significación ():
- El Nivel de Significación () es el complemento del Nivel de Confianza. Representa la probabilidad de error.
- Ejemplo para 95%:
3. Determinar el Área en las Colas (α/2):
- Como la prueba es bilateral (la media podría estar en cualquier lado de la muestra), el error se divide en dos “colas” (extremos) de la distribución.
- Ejemplo para 95%: 0.05 / 2 = 0.025 (área en cada cola).
4. Buscar el Área Acumulada:
- Para encontrar el valor en la tabla, necesitamos el área desde el extremo izquierdo de la curva hasta el valor crítico .
- Ejemplo para 95%: 1− 0.025=0.9750
5. Encontrar el Valor Crítico:
[Tabla de la Distribución Normal]
- Se busca el valor 0.9750 dentro del cuerpo de la tabla y se identifican las coordenadas ( y ).
Valores Z Críticos Más Comunes
En la práctica, los valores de para los niveles de confianza más habituales se memorizan o se consultan rápidamente:
| Nivel de Confianza (NC) | Nivel de Significación () | Valor Crítico |
| 90% | 0.10 | 1.645 |
| 95% | 0.05 | 1.96 |
| 99% | 0.01 | 2.58 |
Ejemplo Detallado para 95%
- NC = 0.95
- α=0.05
- α/2=0.025
- Área a buscar: 1−0.025=0.9750
- Al buscar 0.9750 en la tabla Z, encontramos que corresponde a la fila 1.9 y la columna .06.
- Por lo tanto, el valor crítico Z para 95% es 1.96.
Ejemplos de Cálculo de Tamaño de Muestra
Ejemplo 1: Encuesta de Opinión Pública (Máxima Incertidumbre)
Se desea realizar una encuesta para estimar la proporción de ciudadanos que aprueban la gestión de un alcalde.
- Nivel de Confianza (NC): 95% →Z=1.96
- Margen de Error (E): 5% (0.05)
- Proporción Esperada (P): Desconocida, por lo que se utiliza P=0.5 (máximo conservador).
\begin{align*}
n & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
& = \frac{1.96^2 \times 0.5 \times (1 - 0.5)}{0.05^²} \\
& = 384.16
\end{align*}Respuesta: Se necesita una muestra de 385 personas (redondeando hacia arriba).
Ejemplo 2: Estudio de Mercado (Mayor Precisión)
Una empresa quiere estimar la proporción de clientes que comprarán un nuevo producto, con una mayor precisión que en el ejemplo anterior.
- Nivel de Confianza (NC): 95% →Z=1.96
- Margen de Error (E): 3% (0.03)
- Proporción Esperada (P): Desconocida, se usa P=0.5.
\begin{align*}
n & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
& = \frac{1.96^2 \times 0.5 \times (1 - 0.5)}{0.03^²} \\
& = 1067.11
\end{align*}Respuesta: Se necesita una muestra de 1,068 personas. Nota: Una reducción del error (0.05 a 0.03) aumenta significativamente el tamaño de muestra.
Ejemplo 3: Calidad de Producto (Alto Nivel de Confianza)
Se quiere estimar la proporción de productos defectuosos en una línea de ensamblaje con una alta certeza.
- Nivel de Confianza (NC): 99% →Z=2.58
- Margen de Error (E): 4% (0.04)
- Proporción Esperada (P): Desconocida, se usa P=0.5.
\begin{align*}
n & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
& = \frac{2.58^2 \times 0.5 \times (1 - 0.5)}{0.04^²} \\
& = 1040.06
\end{align*}Respuesta: Se necesita una muestra de 1,041 productos. Nota: Un aumento del nivel de confianza (95% a 99%) aumenta la muestra.
Ejemplo 4: Estudio con Proporción Conocida
Un estudio anterior indicó que la proporción de personas que usan transporte público en una ciudad es del 70%. Queremos validar este dato.
- Nivel de Confianza (NC): 90% →Z=1.645
- Margen de Error (E): 5% (0.05)
- Proporción Esperada (P): 0.70
\begin{align*}
n & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
& = \frac{1.645^2 \times 0.70 \times (1 - 0.70)}{0.05^²} \\
& = 227.306
\end{align*}Respuesta: Se necesita una muestra de 228 personas. Nota: Usar una proporción conocida, si está lejos de 0.5, reduce el tamaño de muestra.
Ejemplo 5: Pequeño Margen de Error (Proporción Conocida)
Se estima la proporción de gamers en una población, con una proporción inicial del 20%, buscando un error muy bajo.
- Nivel de Confianza (NC): 95% →Z=1.96
- Margen de Error (E): 2% (0.02)
- Proporción Esperada (P): 0.20
\begin{align*}
n & = \frac{Z^2 \times P \times (1 - P)}{E^²} \\
& = \frac{1.96^2 \times 0.20 \times (1 - 0.20)}{0.02^²} \\
& = 1536.64
\end{align*}Respuesta: Se necesita una muestra de 1,537 personas.
Ejemplo de Solución (Estimando la Media )
Escenario: Quieres estimar el salario promedio () de los empleados de una empresa que tiene empleados.
- NC: 95% →Z=1.96
- E (Error Aceptable): ±$1,000
Problema: No conoces la Desviación Estándar (σ) de los salarios.
- Estimar σ (Método del Rango):
- Asumes que el salario más bajo (Mín) es $2,000.
- Asumes que el salario más alto (Máx) es $14,000.
- Calcular n0 (Población Infinita):
- Ajuste por Población Finita (N=800):
Resultado: Necesitarías una muestra de 34 empleados para estimar el salario promedio de la empresa con un error de ±$1,000 y una confianza del 95%.